Esta primavera, nuestro bot de business intelligence nos informó con total seguridad que “active engagements” y “open opportunities” eran KPIs distintos, a pesar de que ambos provenían de la misma tabla. Minutos después, contabilizó dos veces los ingresos “invoiced” y “billed” como flujos separados. El problema no era el código, era el lenguaje.
Los modelos de lenguaje grandes (LLMs) se expresan con fluidez, pero a menudo malinterpretan el significado. Cuando los términos de negocio carecen de una ontología compartida, los sinónimos chocan y los resultados se distorsionan. Lo solucionamos añadiendo una capa semántica: un vocabulario de negocio compartido que define las relaciones entre los datos y los modelos. La precisión subió al 98 %, y, lo más importante, la confianza volvió.
Las alucinaciones de IA no son fallas: son riesgos para el negocio
En entornos empresariales, las alucinaciones de IA son algo más que curiosidades: son riesgos para el negocio. Durante el despliegue de nuestro AI Analyst Engine identificamos errores que las pruebas convencionales nunca habían detectado: conteos de personal duplicados cuando “employees” y “users” se trataban como objetos distintos, y ingresos fantasma cuando “contacts” se combinaban con “accounts” entre distintos departamentos.
Datos recientes subrayan este riesgo. Una encuesta de SAP de 2025 reveló que el 55 % de los ejecutivos de EE. UU. ya confía en insights impulsados por IA en lugar de la toma de decisiones tradicional. Casi la mitad afirmó que anularía decisiones planificadas en función de recomendaciones de IA, y el 38 % ya confía en la IA para tomar algunas decisiones de negocio de forma autónoma.
Sin embargo, incluso las pruebas internas de OpenAI muestran que los modelos tienen alucinaciones entre el 33 % y el 70 % del tiempo. Sin controles semánticos —reglas que definan el significado de cada término de negocio— las organizaciones corren el riesgo de automatizar la confusión en lugar del insight.
Más allá de los catálogos de datos: por qué el significado del negocio importa más que los metadatos
Los catálogos de datos organizan lo que tienes; los modelos semánticos definen qué significa. Los modelos de datos tradicionales describen la estructura —tablas, campos, columnas— pero no la intención de negocio que hay detrás. Los modelos de datos semánticos van más allá. Mapean cómo opera el negocio: clientes, contratos, flujos de ingresos y las relaciones entre ellos.
Una capa semántica se sitúa por encima del esquema físico de la base de datos. Conecta cada campo con un vocabulario compartido y un conjunto de reglas de negocio. La integración se vuelve más rápida porque las aplicaciones y la analítica hablan el mismo lenguaje conceptual. Los analistas consultan la intención, no los nombres de las tablas. Las herramientas impulsadas por LLM utilizan un contexto coherente en lugar de depender de conjeturas o joins ambiguos.
Creación de un vocabulario de negocio compartido
Durante nuestro despliegue de Q1 2025 descubrimos que implementar tecnología era más fácil que introducir la terminología.
Ventas los llamaba “tickets”. Soporte decía “cases”. Finanzas alternaba entre “net revenue” y “gross sales”, cada uno con definiciones distintas. Construimos una capa semántica sobre nuestro warehouse en Snowflake usando Cortex Analyst, comenzando por un vocabulario unificado. Cada concepto de negocio se mapeó explícitamente en una ontología basada en YAML y se revisó con expertos de dominio para garantizar la precisión. “Tickets”, “cases” y “service requests” pasaron a ser un único objeto coherente.
Nuestro workbench en Streamlit permitió a los equipos reproducir consultas reales de LLM, revelar malentendidos y resolverlos en el Verified Query Repository, a menudo el mismo día. En seis semanas, la precisión del SQL generado por IA alcanzó el 91,7 %, mientras que el tiempo necesario para incorporar a nuevos analysts se redujo en un 35 %. La capa semántica evolucionó hasta convertirse en el data dictionary autorizado de la empresa. Cuando alguien pide “receipts last quarter”, el sistema ahora vincula su intención con las columnas correctas, los períodos de tiempo adecuados y la lógica de moneda correspondiente, eliminando las conjeturas entre tablas similares.
De esquemas a semántica: incorporando la lógica de negocio en la arquitectura de datos
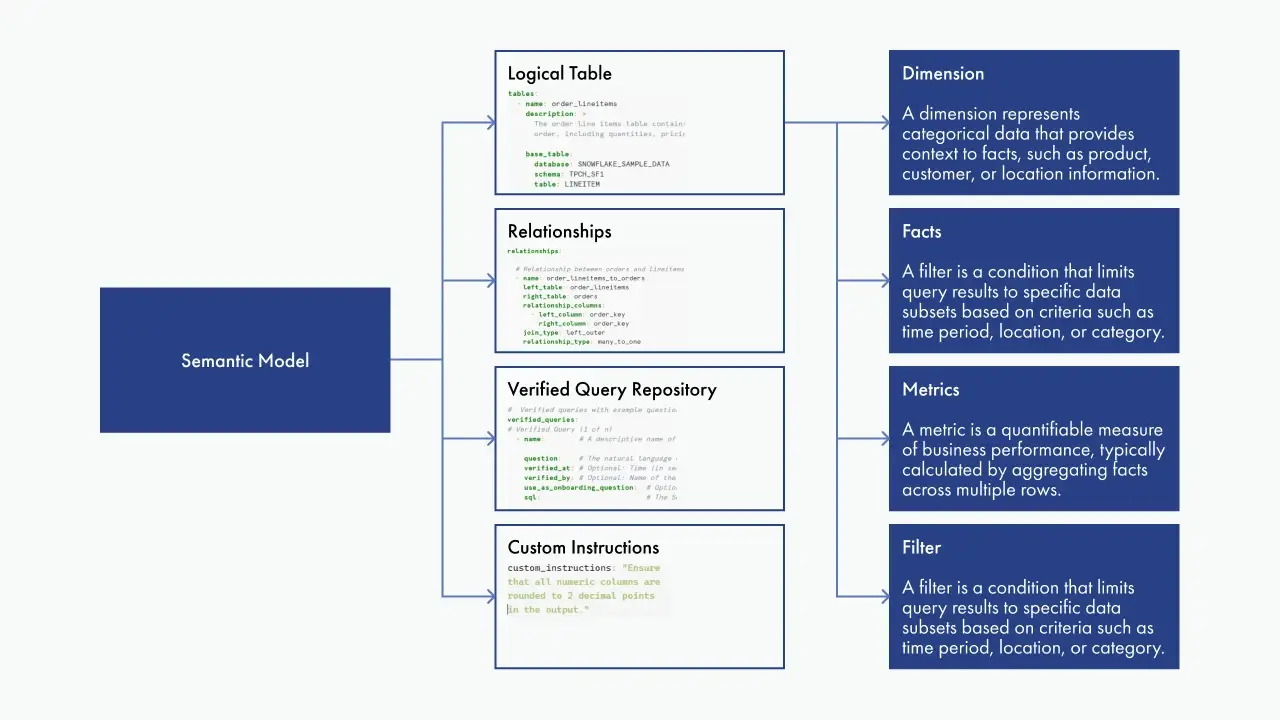
La capa semántica comienza modelando las entidades de negocio como tablas lógicas en Snowflake. Cada tabla lógica representa un concepto familiar, como “Customer” u “Order”, alineado con las tablas o vistas subyacentes del warehouse.
Estas tablas incluyen:
El verdadero valor proviene de definir relaciones a nivel de modelo. Hacer el join de “Customers” y “Orders” sobre “customer_id” permite un análisis limpio por segmento sin tener que navegar la complejidad del esquema en bruto.
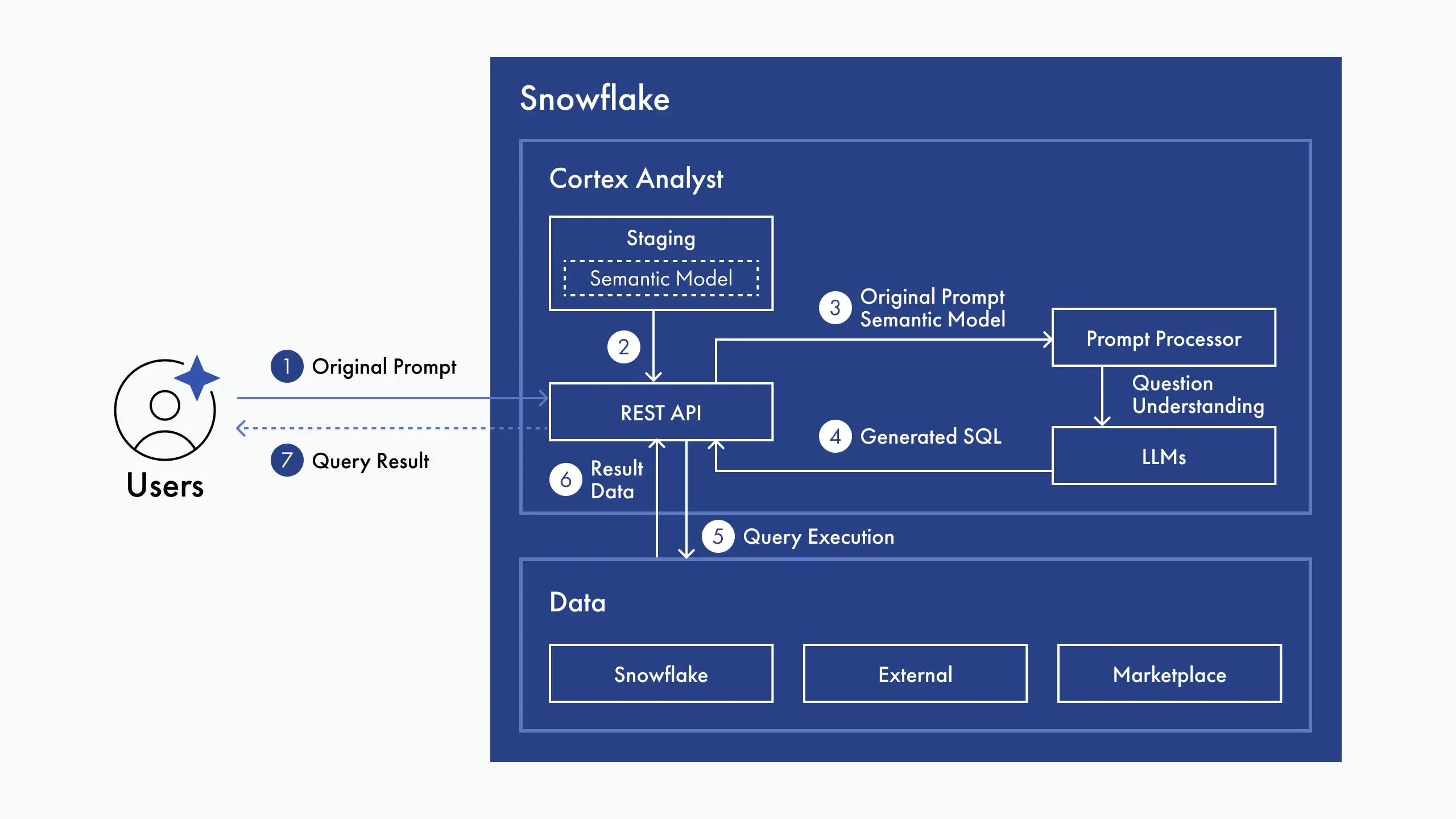
La precisión de las consultas depende del Verified Query Repository (VQR) de Snowflake. Los usuarios de negocio hacen preguntas en lenguaje natural (“Which customers had repeat orders last quarter?”). El repositorio almacena consultas SQL validadas junto con su intención. Cortex Analyst utiliza estos ejemplos, junto con nuestra lógica de workflow, para interpretar correctamente nuevas preguntas.
Esta estructura ofrece un control preciso sobre las reglas de negocio. Redefinir qué es un “active customer” o actualizar una fórmula de lifetime value requiere ajustes semánticos, no reescrituras de código. Los dashboards, la analítica y las reglas de negocio se mantienen sincronizados en toda la organización.
El impacto medible de la alineación semántica
Las métricas posteriores al despliegue confirmaron el valor. Antes, Cortex duplicaba los ingresos cuando “invoiced” y “billed” aparecían como sinónimos en distintas tablas. Inflaba los reportes al combinar “customer” y “contact” como entidades separadas, lo que daba lugar a cuentas empresariales duplicadas.
Tras la alineación semántica, las alucinaciones se redujeron en un 70 %. La precisión de los resultados generados por IA aumentó al 92 %.
El tiempo promedio para obtener insights se redujo de 22 minutos a 5, y los costos de cómputo disminuyeron en casi un 50 %.
La adopción llegó rápidamente. La analítica de autoservicio ahora supera a los reportes creados por analysts en una proporción de cuatro a uno. Los usuarios de negocio pueden acceder directamente a los insights, sin soporte adicional de developers. Los tickets al help desk disminuyeron un 30 %, liberando a dos empleados de tiempo completo para proyectos estratégicos. Finanzas cerró los libros del Q2 dos días antes, posible solo porque los datos finalmente eran coherentes, precisos y estaban alineados con el significado del negocio.
Involucrar a los usuarios de negocio en workshops semánticos desde el inicio fue clave. En futuros proyectos, daremos prioridad a la capacitación temprana de usuarios para acelerar la adopción y construir una confianza duradera.
Primeros pasos: un marco práctico
Los modelos semánticos actúan como disyuntores para los errores de IA. Para implementar uno de forma efectiva:
Elige una métrica crítica. Empieza por algo doloroso cuando está mal; en nuestro caso fue el revenue recognition.
Realiza una auditoría de sinónimos. Reúne equipos multifuncionales. Enumera todos los términos usados para esa métrica—ticket, case, service request. Agrupa duplicados, registra conflictos y construye un diccionario provisional.
Crea bucles de feedback. Implementa el voto de usuarios sobre los resultados de IA, mantén un verified query repository y revisa los cambios con regularidad.
Itera semanalmente. Reproduce consultas reales y corrige los problemas el mismo día. El progreso vale más que la perfección.
Comparte los logros. Publica gráficos de precisión del antes y después. Nada impulsa la adopción como una mejora visible.
Cuando el significado de negocio tiene prioridad, los dashboards, los modelos de IA y el compliance se alinean de forma natural. Tus datos ya contienen las respuestas; un lenguaje compartido garantiza que la IA las interprete correctamente. La elección es sencilla: construye las bases semánticas ahora o sigue depurando alucinaciones. La IA empresarial no solo necesita modelos potentes; requiere un lenguaje compartido que puedan entender tanto humanos como máquinas.










